Electronic Health Information Exchange (HIE) allows doctors, nurses, pharmacists, other health care providers and patients to appropriately access and securely share a patient’s vital medical information electronically – improving the speed, quality, safety, and cost of patient care.
HIE enables electronical movement of clinical information among different healthcare information systems. The goal is to facilitate access to and retrieval of clinical data to provide safer and more timely, efficient, effective, and equitable patient-centered care.
While the importance of HIE is clearly visible, now the important question is how hospitals can collaborate to form an HIE and how the HIE will consolidate data from disparate patient information sources. This brings us to the important discussion of HIE data models.
HIE Data Models
There are multiple ways in which an HIE can get its data, each influencing the way in which the interoperability goals are achieved, how easily an HIE platform is built and how to sustain in the long run especially if the number of hospitals in the ecosystem increases. The two models are
⦁ Centralized
⦁ De-centralized
Centralized HIE Data Model
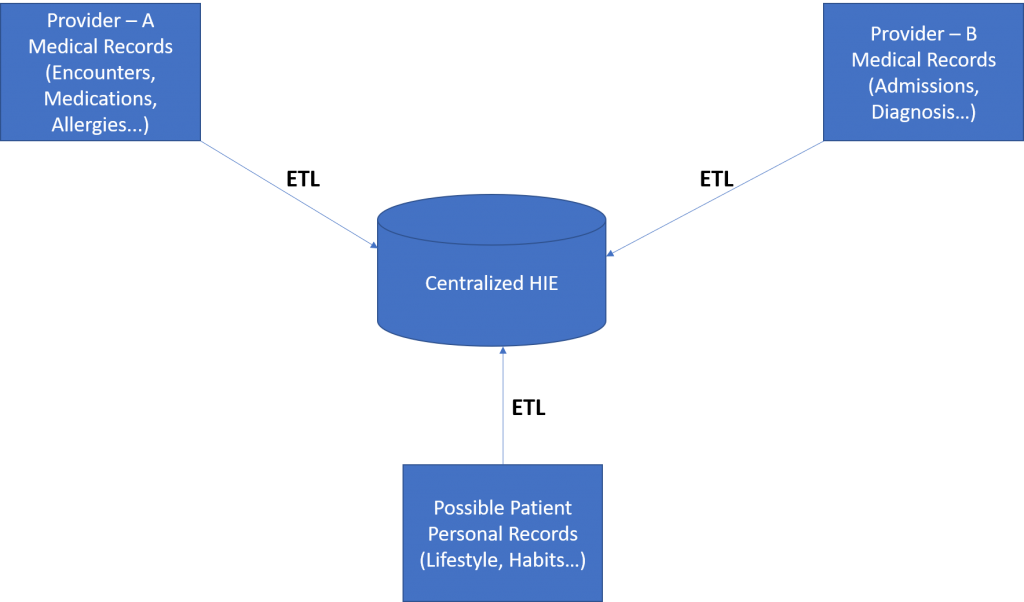
This is a pictorial representation of centralized HIE data model.
As evident, in the centralized model, all the stakeholders send their data to a centralized location and typically a ETL (Extraction, Transformation, and Loading) process ensures that all the data is synced with the centralized server.
Advantages
- From the query performance perspective this model is one of the most efficient, because the DBAs have complete control of the data and with the techniques like partitioning, indexing they could ensure that the query can be done in the best possible manner. Since the hardware is fully owned by a single organization (which is the HIE itself), this can be scaled out or scaled up to meet the demands of the business.
- This model is fairly self-sufficient once the mechanism for the data transfers are established, as the need to connect to individual hospitals are no longer there.
- Smaller hospitals in the ecosystem need not take the burden of maintaining their data and interoperability needs and can just send their data to the centralized repository.
- Better scope for performing population predictive and prescriptive analytics as the data resides in one place and easier to create models based on the historical data.
Limitations
- This model needs to have highest level of security built in, because any breach in the system will compromise the data of entire ecosystem. Also considering that individual hospitals send their data to this model, all the responsibility lies with a single agency (HIE) which is highly prone to lawsuits related to data privacy and confidentiality.
- There is no control for patients in managing their own records and right to provide consent for data access, even though this information can be collected there is no easy way to implement them.
- The system is prone to a single point of failure and hence require efforts for high availability of the platform.
- This model will face scalability challenges as the network grows beyond a point, unless the platform is modernized with latest big data databases, the system will have scalability issues.
- Lot of coordination required to monitor the individual ETL jobs for their success, failure, and record synchronization details, so this model will have a huge allocation of IT resources and will increase the total cost of ownership.
- The model of expense sharing between the HIE, data producers, data consumers will be difficult and needs to have a strong governance model.
- Difficult to match the patient information across hospitals, unless the both the hospitals use deterministic matching attributes like SSN, otherwise it would be difficult to match between patients who have misspelt names, different addresses etc.
- This model may suffer data integrity issues when the participant hospitals merge with each other, such that the IT systems of the two hospitals need to take care the internal details of the ETL jobs.
De-centralized HIE Data Model
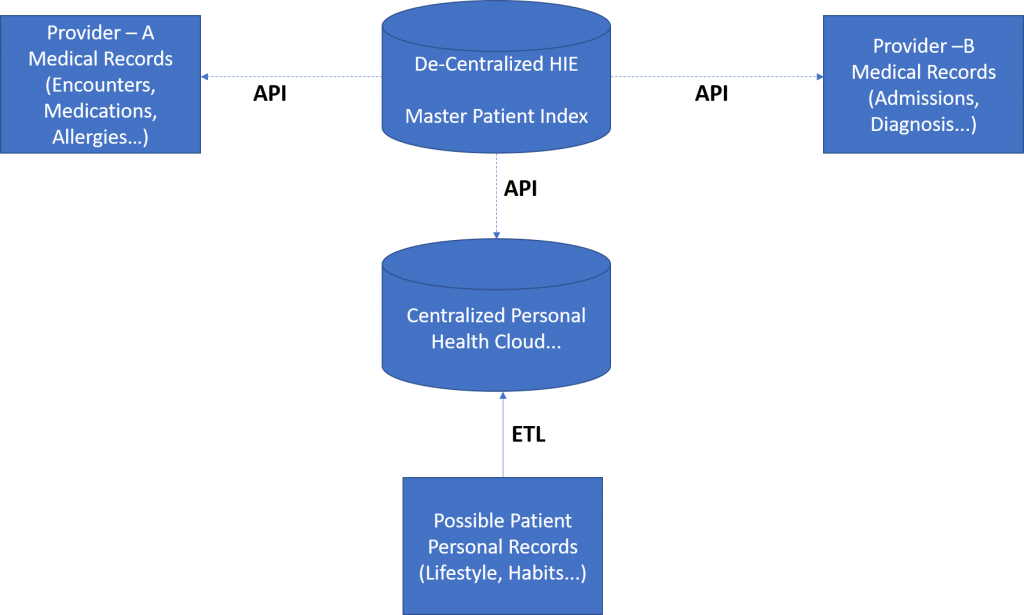
The above is the pictorial representation of decentralized HIE data model.
As evident, in this model individual hospitals, continue to own all their data, however, the centralized database keeps a pointer – MPI (Master Patient Index), which serves as a unifying factor for consolidating data for that patient. While some books also suggest a variant called Hybrid model which combines centralized and decentralized data models, we believe that pure-play decentralized model itself is a hybrid (i.e. centralized + decentralized) because there needs to be a centralized repository to keep the master patient index along with all the access rights and related information.
Advantages
- It is much easier to implement as no huge investment is required from a centralized provider perspective. The HIEs in this model can start low and grow on demand basis
- Less expensive as no single organization owns all the data, but only a pointer to the data and the respective hospitals continue to own the data.
- Much easier to provide patients the control of their own data and patient’s consent can be a key in accessing information from the respective hospitals.
- No need to worry about broken ETL jobs and the latency between source and destination. All the data is always current.
- No need to worry about single point of failure, as the individual sub systems will continue to exist even if one link to a particular hospital is broken. Maintaining the high availability of this light-weight platform is much easier than a monolithic large database as part of a centralized data model.
- A data breach into the centralized repository still will not compromise all the data, as the individual hospitals are likely to have some more additional controls which prevent a free flow for hackers. This also prevents one organization from facing all the legal issues resulting from patient data breach.
Limitations
- This model will have a query performance problem when it comes to aggregating a patient information across multiple hospitals, because each has to be obtained with a separate API call and a facade has to group multiple datasets.
- Difficult to establish common standards in terms of data formats and APIs across multiple hospitals, this may result in each hospital having their own methods.
- Bringing all the stakeholders including the patients to agree on a MPI (Master Patient Index) will have governance challenges and needs to be implemented carefully.
- Providing analytics for a large set of population will have challenges due to the difficulties in consolidating the data.
Our Point of View & Role of Blockchain
While no model can be 100% perfect for building an HIE, our analysis point to that fact decentralized model of building and operating HIE is better than centralized model. The COVID pandemic has changed the world and the boundaries of healthcare no longer exist within a smaller geography or neighbourhood as it used to. More the participants and bigger the network size, the better it is for population health improvement initiatives. Also, in high population countries where there are initiatives like national healthcare for all, these larger initiatives cannot be done using a pure-play centralized model.
From an implementation perspective, the Healthcare IT world has been curiously watching the role of Blockchain in data interoperability and in the implementation of decentralized HIE. Blockchain which is a distributed database has decentralization built-in as part of its core architecture. It would be easier to implement decentralized HIE using blockchain.
Our Reference Implementation Rhodium to cater to Healthcare Data Management and Interoperability has positioned Blockchain as a core mechanism for patient data sharing, we will share more of our thoughts and details of reference implementation in the coming articles in this series.
About the Author –

Srinivasan Sundararajan
Srini is the Technology Advisor for GAVS. He is currently focused on Data Management Solutions for new-age enterprises using the combination of Multi Modal databases, Blockchain and Data Mining. The solutions aim at data sharing within enterprises as well as with external stakeholders.
Back to blogs