We have been hearing and using the term ‘Big Data’ for a while. Though there could be multiple interpretations of it, one common explanation is, Big Data represents the acquisition, storage, and processing of massive quantities of data beyond what traditional enterprises used to. Also, the data need not be in conformity to any schema, business rules or structure.
With the growth of Hyper Scale Cloud Data Platforms, the term ‘massive data’ has taken a back seat. Because in today’s cloud context any database platform can grow to a massive scale. Hence, Big Data can now be referred to as unstructured data which is not in conformance with enterprise business rules, quality constraints, and formats.
While Big Data analytics will continue to grow in enterprises to provide more insights to businesses, we have spotted a different trend.

From Big to Small &Wide Data
In their annual report of “Data And Analytics Trends for 2021”, leading analyst firm Gartner has featured the trend– “From Big to Small and Wide Data”.Gartner further defines that, “Small and wide data, as opposed to big data, solves several problems for organizations dealing with increasingly complex questions on AI and challenges with scarce data use cases.”
Gartner predicts that by 2025, 70% of organizations will shift their focus from big to small and wide data, “providing more context for analytics and making AI less data hungry.”
Now the big question is what is Small Data?
What is Small Data?
Emerging trends do not always have a perfect definition. Let us analyze various definitions and settle for the best.
As per Gartner, “Small data is an approach that requires less data but still offers useful insights. The approach includes certain time-series analysis techniques or few-shot learning, synthetic data, or self-supervised learning.”
Some examples of areas of potential application for small and wide data are demand forecasting in retail, real-time behavioral and emotional intelligence in customer service applied to hyper-personalization, and customer experience improvement.
However, based on our point of view, small data emphasize on the role of Master Data Management within the scope of enterprise. Master Data is key to the success of AI-driven insight. It has more to do with smaller sets of cleaned and enriched data than huge quantities of data. Wide data is about linking Master Data with additional data that provides a 360-degree view of the subject of interest.
The combination of Master Data along with the enriched information available in the form of data linkages and 360-degree together could be termed as small and wide data. It makes sense for enterprises to concentrate more on small data i.e. MDM and wide data i.e. 360-degree views, as part of their data management strategy.
Data Fabric As The Foundation Platform
Analysts recommend that data fabric is foundational to delivering deeper insights and improving the customer experience for enterprises. Solutions in MDM and CRM are recommended to accelerate the time to value curating data for use.
Data fabric, as a data management design concept, is a direct response to long-standing data integration challenges faced by data and analytics leaders in a highly distributed and diverse data landscape.
Since Data Fabric enables support for small data in the form of Master Data Management and Wide Data in the form of360-degree views, organizations should consider fitment of Data Fabric frameworks as part of their enterprise data management strategy.
Master Data Helps with Real-Time Processing Needs
As explained from the above trends, the role of Master Data Management is crucial for organizations from their future data management strategy perspective, especially with the shift from Big Data to Small and Wide Data. Also, from the existing real-time processing perspective Master Data has an important role.
Real-time processing deals with streams of data that are captured in real-time and processed with minimal latency to generate real-time (or near real-time) reports or automated responses.
The Kappa Architecture is a software architecture used for processing streaming data. The main premise behind the Kappa Architecture is that you can perform both real-time and batch processing, especially for analytics, with a single technology stack. The following diagram gives an overview of the Kappa Architecture.
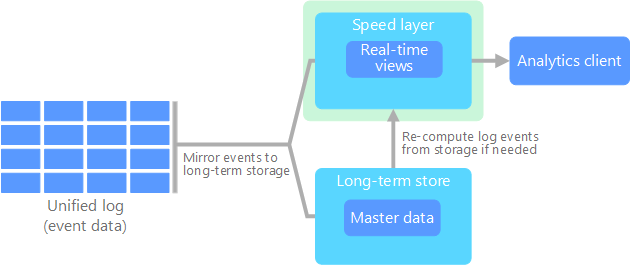
As evident from the architecture, the role of Master Data is significant in real-time processing scenarios also.
Unstructured big data continues to play a big role in enterprise insights. However, even more, important is to augment the big data processing with more meaningful data is subject to data quality rules, constraints and de-duplicated in the form of Master data. The importance of the Master Data Management is evident from the trends that show shift from Big Data to Small and Wide Data.
About the Author –

Srinivasan Sundararajan
Srini is the Technology Advisor for GAVS. He is currently focused on Healthcare Data Management Solutions for the post-pandemic Healthcare era, using the combination of Multi Modal databases, Blockchain and Data Mining. The solutions aim at Patient data sharing within Hospitals as well as across Hospitals (Healthcare Interoprability), while bringing more trust and transparency into the healthcare process using patient consent management, credentialing and zero knowledge proofs. Back to blogs
